Sensor Foundation Models
Making the most of wearable sensor signals
Wearable sensors have become ubiquitous thanks to a variety of health tracking features. The resulting continuous and longitudinal measurements from everyday life generate large volumes of data. However, making sense of and leveraging these often unlabeled observations for actionable insights is non-trivial. Inspired by the success of pre-trained generalist models in the image and vision domains we developed a suite of Large Sensor Models (LSM), a class of foundation model tailored for wearable sensor data.
Proving Scaling in The Sensor Domain.
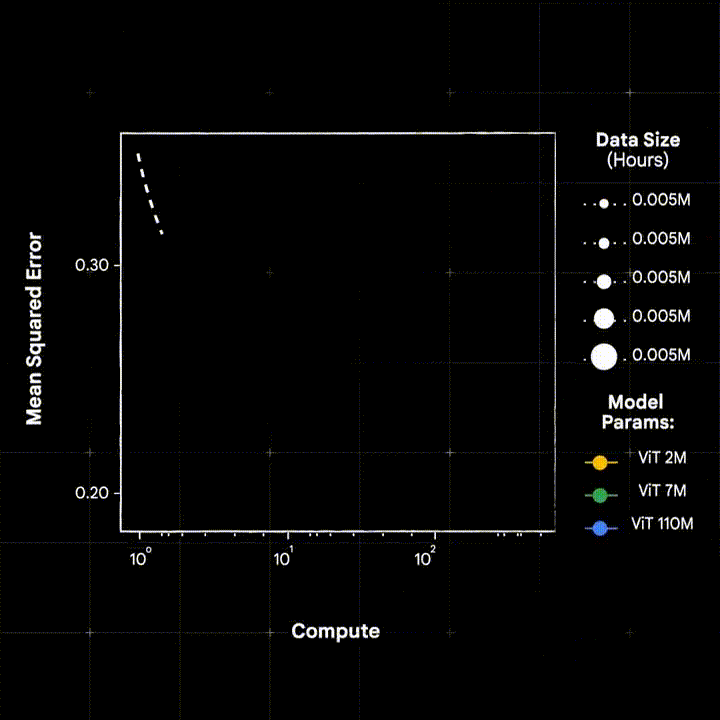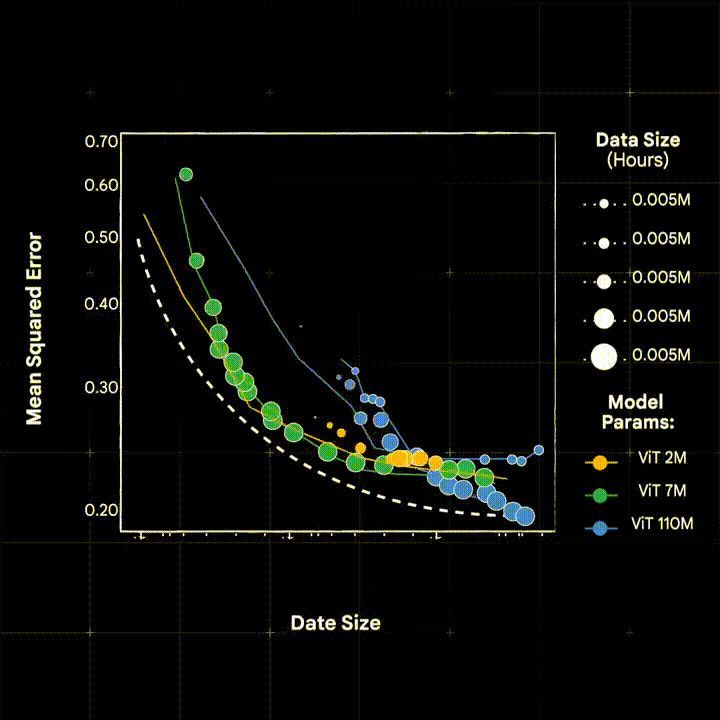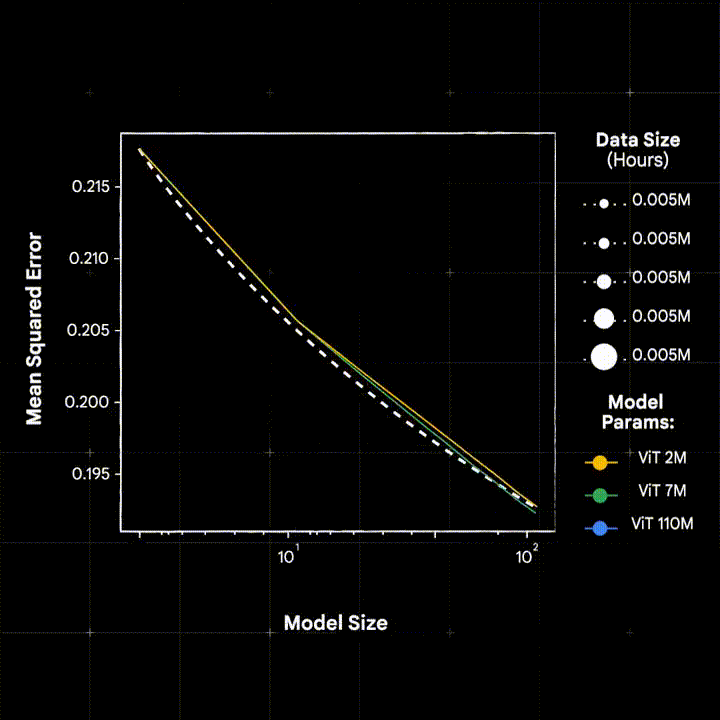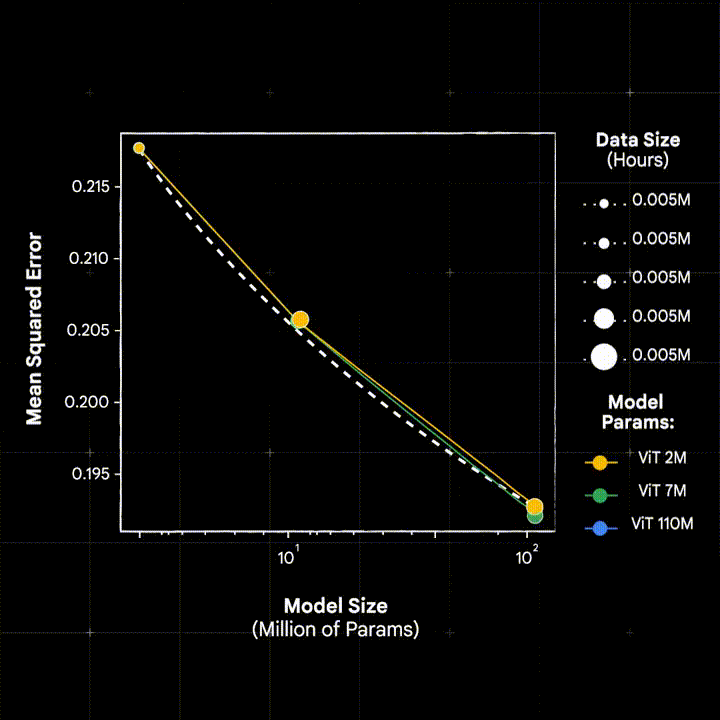
The success of large scale pre-training, as shown in the language and vision domains, is (in large part) driven by the ability of these models to scale – where pre-trained models improves monotonically as data, model capacity, and compute resources are increased.
In our ICLR’25 paper, Scaling Wearable Foundaiton Models (Narayanswamy* et al., 2025) we show, for the first time, that scaling laws apply in the wearable sensor domain. In so doing we introduce LSM-1 and explore the effects of large-scale pre-training on a number of health related downstreams including activity recognition, mood classification, and modeling human physiology.


Handling Missing Data.
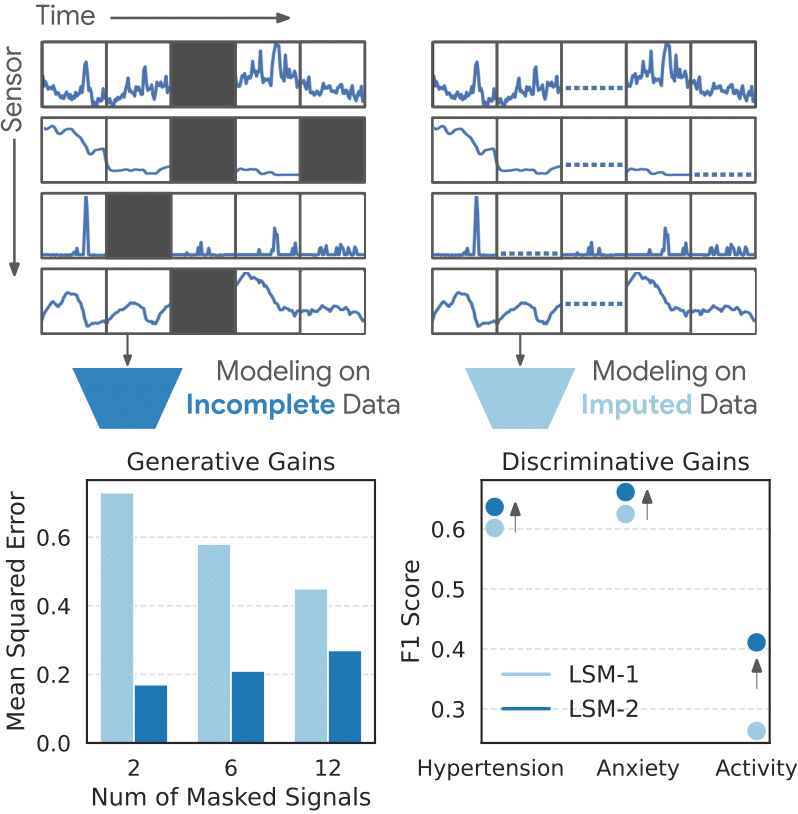
Building on the success of LSM-1 we explored new strategies to improve the scaling of sensor foundaiton models. To do so we tackle an inevitable pitfall of data missingness. Wearable sensor data is naturally fragmented, with missingness occuring for a number of reasons (battery drain,device removal/charging, environmental/electromagnetic noise, etc.). While previous approaches handled data missingness with imputation or data filtering, developing more elegant methods of handling this fundemental aspect of sensor signals ensures that LSM-like can leverage as much real data as possible.
In our paper LSM-2: Learning from Incomplete Wearable Sensor Data (Narayanswamy* et al., 2025), submitted to NeurIPS’25, we introduce AIM (adaptive and inherited masking), a means of cleverly leveraging masked-pretraining and the encoder’s attention mask to ignore missing segments of data.

In so doing we develop LSM-2, the second iteration of our Large Sensor Model family. We find that LSM-2 more efficiently learns from wearable sensor data and improves upon the scaling characteristics of its predecessor. We additionally extended downstream capabilities of the model to include 20-class activity recognition, hypertension and anxiety detection, insulin resistance regression.

Learning the Language of Sensor Signals.
Though sensor encoders are powerful tools in enabling activity tracking and disease detection, sensor signals are inherently difficult to interpret. For example, you would be easily able to differentiate a picture of a dog from that of a cat, but differentiating the HR signature of a runner from that of a mountain biker would prove less intuitive. To improve the explainability of sensor data we explored how best to correlate representations of sensor data with human language.
In our NeurIPS’25 submission SensorLM: Learning the Language of Wearable Sensors (Zhang et al., 2025), we explore the pair-wise training of wearable sensor data with written descriptions of the data. In so doing we develop SensorLM. SensorLM extends the CoCa framework and integrates both a contrastive similarily to loss in addition to a captioning loss. In so doing SensorLM enables improved zero-shot classification, generalization to new health classes, cross modal retrieval, and caption generation for sensor data.